Lambda表达式 Java8新引入的新特性 Lambda表达式。Lambda表达式是一种用于取代匿名类,把函数行为表述为函数式编程风格的一种匿名函数。Lambda表达式的执行结果是函数式接口的一个匿名对象 。
是一套关于函数(f(x))定义、输入量、输出量的计算方案
语法格式 概述 (parameters) -> { statements; } //实例 (int a, int b) -> {return a + b;}
parameters :函数的参数列表
statements; :执行语句
-> :使用指定参数去完成某个功能
(parameters) -> expression //实例 (int a, int b) -> a + b
parameters :函数的参数列表
expression :表达式
-> :使用指定参数去完成某个功能
特点
可选的大括号{}
函数体只包含一个语句,不需要大括号
// 1.函数体只有一个语句,省略大括号 (String msg) -> System.out.println("hello"+ msg);
可选的参数圆括号()
只有一个参数,省略圆括号,同时省略类型
// 2.只有一个参数,省略圆括号,同时省略类型 msg -> System.out.println("hello “ + msg);
可选的返回关键字return
函数体只有一个表达式,且运算结果匹配返回类型
// 3.函数体只有一个表达式,省略return (int a, int b) -> a + b
可选的类型声明
不需要参数类型,编译器可以根据参数值进行推断
// 4. 省略参数类型,编译器可以进行推断 (a, b) -> a + b
常见的函数式接口 函数式接口必须有一个前提,有且只有一个抽象方法的接口,并且有@FunctionnalInterface注解
实例
@FunctionalInterface public interface IMathOperation { int operation (int a, int b) ;}@FunctionalInterface public interface IGreeting { void sayHello (String message) ;} @FunctionalInterface public interface Runnable { public abstract void run () ;}@FunctionalInterface public interface Supplier <T> { T get () ;}
Runnable / Callable 创建线程
public class RunnableLambda { public static void main (String[] args) { new Thread (new Runnable () { @Override public void run () { String name = Thread.currentThread().getName(); System.out.println(name + " 线程已启动" ); } }).start(); new Thread (() -> { String name = Thread.currentThread().getName(); System.out.println(name + " 线程已启动" ); }).start(); new Thread (() -> System.out.println(Thread.currentThread().getName() + " 线程已启动" )).start(); } }
Supplier / Consumer Supplier(消费者)
public class SupplierLambda { public static void main (String[] args) { int arr[] = {2 , 3 , 4 , 52 , 333 , 23 }; int maxNum = getMax(() -> { int max = arr[0 ]; for (int i : arr) { if (i > max) { max = i; } } return max; }); System.out.println(maxNum); } public static int getMax (Supplier<Integer> sup) { return sup.get(); } }
Consumer(消费者)
import java.util.Arrays;import java.util.Locale;import java.util.function.Consumer;public class ConsumerLambda { public static void main (String[] args) { consumerString( s -> System.out.println(s.toLowerCase()), s -> System.out.println(s.toUpperCase()) ); } static void consumerString (Consumer<String> function) { function.accept("Hello" ); } static void consumerString (Consumer<String> one, Consumer<String> two) { one.andThen(two).accept("Hello" ); } }
Comparator 比较器
import java.util.Arrays;import java.util.Comparator;public class ComparatorLambda { public static void main (String[] args) { String[] strs = {"dedeyidede" , "abc" , "de" , "fghi" }; Comparator<String> comparator = new Comparator <String>() { @Override public int compare (String o1, String o2) { return o1.length() - o2.length(); } }; Arrays.sort(strs, (s1, s2) -> s1.length() - s2.length()); System.out.println(Arrays.toString(strs)); } }
Predicate 判断逻辑关系
import java.util.function.Predicate;public class PredicateLambda { public static void main (String[] args) { andMethod(s -> s.contains("H" ), s -> s.contains("W" )); orMethod(s -> s.contains("H" ), s -> s.contains("w" )); negateMethod(s -> s.length() < 5 ); } static void andMethod (Predicate<String> one, Predicate<String> two) { boolean isValid = one.and(two).test("Helloworld" ); System.out.println("字符串符合要求吗:" + isValid); } static void orMethod (Predicate<String> one, Predicate<String> two) { boolean isValid = one.or(two).test("Helloworld" ); System.out.println("字符串符合要求吗:" + isValid); } static void negateMethod (Predicate<String> predicate) { boolean veryLong = predicate.negate().test("HelloWorld" ); System.out.println("字符串很长吗:" + veryLong); } }
Function 方法
import java.util.function.Function;public class FunctionLambda { public static void main (String[] args) { method(str -> Integer.parseInt(str) + 10 , i -> i *= 10 ); String str = "张三,3" ; int age = getAgeNum(str, s -> s.split("," )[1 ], s -> Integer.parseInt(s), n -> n += 100 ); System.out.println(age); } static void method (Function<String, Integer> one, Function<Integer, Integer> two) { int num = one.andThen(two).apply("10" ); System.out.println(num + 20 ); } static int getAgeNum (String str, Function<String, String> one, Function<String, Integer> two, Function<Integer, Integer> three) { return one.andThen(two).andThen(three).apply(str); } }
Lambda的底层实现 ==其本质就是匿名子类的匿名对象 ==
示例代码 需求:遍历List集合
使用Lambda表达式 public class LambdaTest { public static void main (String... args) { List<String> strList = Arrays.asList("L" ,"a" ,"m" ,"b" ,"d" ,"a" ); strList.forEach(s -> { System.out.println(s); }); } }
使用匿名内部类 那么,我们可以使用匿名内部类的形式来实现上述lambda表达式的功能,以下代码的功能一致的:
public class LambdaTest2 { public static void main (String... args) { List<String> strList = Arrays.asList("L" ,"a" ,"m" ,"b" ,"d" ,"a" ); strList.forEach(new Consumer <String>() { @Override public void accept (String s) { System.out.println(s); } }); } }
示例代码分析 forEach()是Iterable接口的一个默认方法,它需要一个Consumer类型的参数,方法体中是一个for循环,对迭代器的每一个对象进行遍历,处理方法就是调用参数对象的accept()方法:
default void forEach (Consumer<? super T> action) { Objects.requireNonNull(action); for (T t : this ) { action.accept(t); } }
继续查看Consumer的accept(T)方法,可以看到Consumer是一个函数式接口(只有一个抽象方法的接口,java8中称之为函数式接口),只有一个抽象方法accept(T)。
@FunctionalInterface public interface Consumer <T> { void accept (T t) ; }
我们对照一下示例代码:
strList.forEach(s -> {System.out.println(s);});
可以大胆的猜测,Lambda表达式
s -> {System.out.println(s);}相当于是实现了Consumer接口的一个匿名(内部类)对象,
而大括号里面的内容:System.out.println(s);相当于重写了accept()的方法体。
反编译lambda表达式代码
对包含lambda表达式的class文件进行反编译时需要注意:
jad系列的反编译工具不支持jdk1.8,所以这里使用CFR进行反编译。
cfr下载地址 :http://www.benf.org/other/cfr/
语法:java -jar cfr-0.145.jar LambdaTest.class --decodelambdas false
反编译后可以得到:
import java.io.PrintStream;import java.lang.invoke.LambdaMetafactory;import java.util.Arrays;import java.util.List;import java.util.function.Consumer;public class LambdaTest { public static void main (String ... args) { List<String> strList = Arrays.asList("L" ,"a" ,"m" ,"b" ,"d" ,"a" ); strList.forEach((Consumer<String>)LambdaMetafactory.metafactory( null , null , null , (Ljava/lang/Object;)V, lambda$main$0 (java.lang.String ), (Ljava/lang/String;)V)()); } private static void lambda$main$0 (String s) { System.out.println(s); } }
反编译结果可以看出,lambda表达式就是一个对象实例,使用什么函数式接口接收的,就是什么对象实例,例如上面的Consumer。
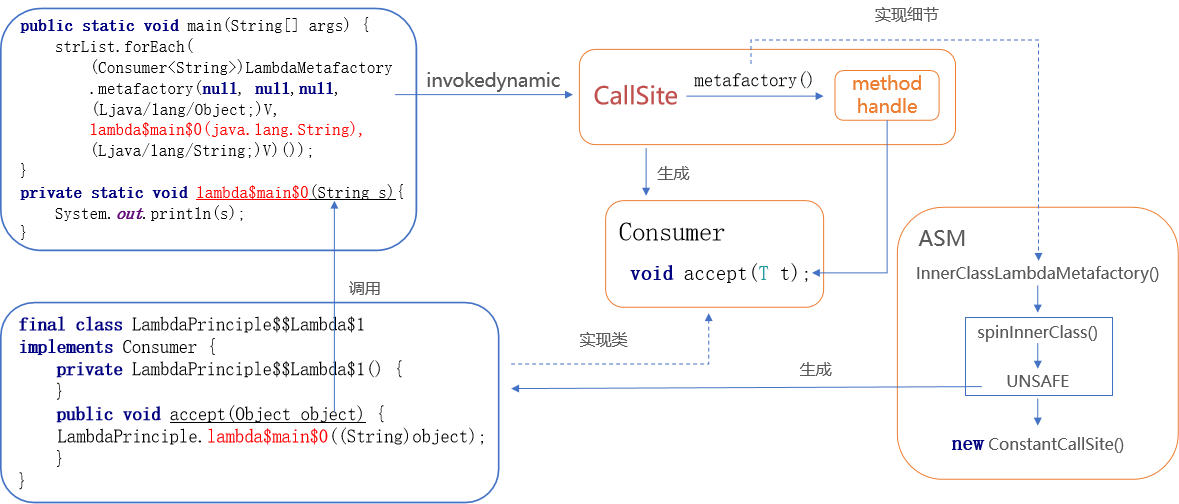
在forEach()方法中,其实是调用了java.lang.invoke.LambdaMetafactory#metafactory()方法,该方法的第5个参数implMethod指定了方法实现。可以看到这里其实是调用lambda$main$0()方法进行输出。跟踪metafactory()方法(参数较多,可以跳过):
public static CallSite metafactory ( // 调用者(LambdaTest)可访问权限的上下文对象,JVM自动填充 MethodHandles.Lookup caller, // 要执行的方法名,即Consumer.accept() ,JVM自动填充 String invokedName, MethodType invokedType, MethodType samMethodType, MethodHandle implMethod, MethodType instantiatedMethodType) throws LambdaConversionException { AbstractValidatingLambdaMetafactory mf; mf = new InnerClassLambdaMetafactory (caller, invokedType, invokedName, samMethodType, implMethod, instantiatedMethodType, false , EMPTY_CLASS_ARRAY, EMPTY_MT_ARRAY); mf.validateMetafactoryArgs(); return mf.buildCallSite(); }
其中new InnerClassLambdaMetafactory看起来是创建了一个Lambda相关的内部类 ,继续跟踪下去:
public InnerClassLambdaMetafactory (...) throws LambdaConversionException { lambdaClassName = targetClass.getName().replace('.' , '/' ) + "$$Lambda$" + counter.incrementAndGet(); cw = new ClassWriter (ClassWriter.COMPUTE_MAXS); }
(省略了一部分代码。)
一看到lambdaClassName这样的变量名就知道它代表的什么意思——Lambda表达式对应的类名,而ClassWriter对象cw,暴露了Lambda表达式的底层实现机制:ASM技术(Assembly,Java字节码操作和分析框架 ,用于在程序运行时动态生成和操作字节码文件)。在这个构造方法里,初始化了大量的ASM技术需要的成员变量,为后续生成字节码的相关操作完成了一系列的初始化动作。现在大致可以猜测:Lambda表达式底层是通过一个内部类来实现的,这个类由ASM技术在程序运行时动态生成,它实现了函数式接口(例如Consumer等),并重写了对应的抽象方法(如accept)。
验证猜想 回到metafactory()方法中,跟踪方法结尾的返回语句mf.buildCallSite();——创建调用点,这才是重点:
@Override CallSite buildCallSite () throws LambdaConversionException { final Class<?> innerClass = spinInnerClass(); try { Object inst = ctrs[0 ].newInstance(); return new ConstantCallSite (MethodHandles.constant(samBase, inst)); } }
方法的注释非常清晰的告诉我们,这个方法在运行期 会返回一个函数式接口的实例,也就是Consumer接口的匿名对象。
方法体的第一行spinInnerClass(),就使用ASM技术生成了一个Class文件,然后使用sun.misc.Unsafe将该类加载到JVM(创建并返回该类的Class对象):
private final ClassWriter cw; private Class<?> spinInnerClass() throws LambdaConversionException { cw.visit(, , lambdaClassName, null , , interfaces); for ( ; ; ) { cw.visitField( , , , null , null ); } generateConstructor(); cw.visitMethod( , , , null , null ); cw.visitEnd(); final byte [] classBytes = cw.toByteArray(); if (dumper != null ) { AccessController.doPrivileged(new PrivilegedAction <Void>() { @Override public Void run () { dumper.dumpClass(lambdaClassName, classBytes); return null ; } }, null , new FilePermission ("<<ALL FILES>>" , "read, write" ), new PropertyPermission ("user.dir" , "read" )); } return UNSAFE.defineAnonymousClass(targetClass, classBytes, null ); }
这个方法的后半部分,if (dumper != null) 代码块给我们提供了将该内部类转储到本地磁盘用以调试的可能,在LambdaTest的main方法里里添加一行代码,将Lambda表达式对应的内部类转储到指定目录(IDEA):
System.setProperty("jdk.internal.lambda.dumpProxyClasses" , "out/production/" );
程序运行之后 ,会将Lambda表达式对应的内部类文件生成出来com.boxuegu.intermediate.language.sugar.lambda.LambdaTest$$Lambda$1:
反编译这个类,代码如下:
可以理解为lambda表达式最终的结果就是生成了以下代码,一个实现了函数式接口的类
import java.lang.invoke.LambdaForm;import java.util.function.Consumer;final class LambdaTest$$Lambda$1 implements Consumer { private LambdaTest$$Lambda$1 () { } @LambdaForm .Hidden public void accept (Object object) { LambdaTest.lambda$main$0 ((String)object); } }
现在我们初步得到了一些结论:
Lambda表达式底层是用内部类来实现的
该内部类实现了某个(根据Lambda所属的代码指定) 函数式接口,并重写了该接口的抽象方法
该内部类是在程序运行时使用ASM技术动态生成的,所以编译期没有对应的.class文件,但是我们可以通过设置系统属性将该内部类文件转储出来
Lambda表达式编译和运行过程 至此,我们只窥视了Lambda表达式底层实现的冰山一角。接下来会有一堆概念和过程!
Java7在JSR(Java Specification Requests,Java 规范提案) 292 中增加了对动态类型语言的支持,使得Java也可以像C语言 那样将方法作为参数传递,其实现在java.lang.invoke包中。它的核心就是invokedynamic指令,为后面函数式编程 和响应式编程 提供了前置支持。
invokedynamic指令对应的执行方法会关联到一个动态 调用点对象(java.lang.invoke.CallSite),一个调用点(call site)是一个方法句柄(method handle,调用点的目标)的持有者,这个调用点对象会指向一个具体的引导方法(bootstrap method,比如metafactory()),引导方法成功调用之后,调用点的目标将会与它持有的方法句柄的引用永久绑定,最终得到一个实现了函数式接口(比如Consumer)的对象。Lambda表达式在编译期进行脱糖(desugar),它的主体部分会被转换成一个脱糖方法(desugared method,即lambda$main$0),这是一个合成方法,如果Lambda没有用到外部变量,则是一个私有的静态方法,否则将是个私有的实例方法——synthetic 表示不在源码中显示,并在Lambda所属的方法(比如main方法)中生成invokedynamic指令。
进入运行期 ,invokedynamic指令会调用引导方法metafactory()初始化ASM生成内部类所需的各项属性,然后由spinInnerClass()方法组装内部类并用Unsafe加载到JVM,通过构造方法实例化内部类的实例(Lambda的实现内部类的构造是私有的,需要手动设置可访问属性为true),最后绑定到方法句柄,完成调用点的创建。你可以把调用点看成是函数式接口(例如Consumer等)的匿名对象,当然,内部类是确实存在的——比如final class LambdaTest$$Lambda$1 implements Consumer。值得注意的是,内部类的实现方法里并没有Lambda表达式的任何操作,它不过是调用了脱糖后定义在调用点目标类(targetClass,即LambdaTest类)中的合成方法(即lambda$main$0)而已,这样做使得内部类的代码量尽可能的减少,降低内存占用,对效率的提升更加稳定和可控。
Lambda表达式的语法糖结论 Lambda表达式在编译期脱去糖衣语法,生成了一个“合成方法”,在运行期,invokedynamic指令通过引导方法创建调用点,过程中生成一个实现了函数式接口的内部类并返回它的对象,最终通过调用点所持有的方法句柄完成对合成方法的调用,实现具体的功能。
Lambda表达式是一个语法糖,但远远不止是一个语法糖。
Lambda表达式并不是JVM原生的语法,底层是通过一个内部类来实现的,这个类由ASM技术在程序运行时动态生成,它实现了函数式接口(例如Consumer等),并重写了对应的抽象方法(如accept)。
方法引用 在使用Lambda表达式的时候,我们实际上传递进去的代码就是一种解决方案:拿什么参数做什么操作。那么考虑一种情况:如果我们在Lambda中所指定的操作方案,已经有地方存在相同方案,那是否还有必要再写重复逻辑?
冗余的Lambda场景 来看一个简单的函数式接口以应用Lambda表达式:
@FunctionalInterface public interface Printable { voidprint(Stringstr); }
在Printable接口当中唯一的抽象方法print接收一个字符串参数,目的就是为了打印显示它。那么通过Lambda来使用它的代码很简单:
public class Demo01PrintSimple { private static void printString (Printable data) { data.print("Hello, World!" ); } public static void main (String[] args) { printString(s ‐> System.out.println(s)); } }
其中 printString 方法只管调用 Printable 接口的 print 方法,而并不管 print 方法的具体实现逻辑会将字符串打印到什么地方去。而 main 方法通过Lambda表达式指定了函数式接口 Printable 的具体操作方案为:拿到 String(类型可推导,所以可省略)数据后,在控制台中输出它。
问题分析 这段代码的问题在于,对字符串进行控制台打印输出的操作方案,明明已经有了现成的实现,那就是 System.out对象中的 println(String) 方法。既然Lambda希望做的事情就是调用 println(String) 方法,那何必自己手动调用呢?
用方法引用改进代码 能否省去Lambda的语法格式(尽管它已经相当简洁)呢?只要“引用”过去就好了:
public class Demo02PrintRef { private static void printString (Printable data) { data.print("Hello, World!" ); } public static void main (String[] args) { printString(System.out::println); } }
请注意其中的双冒号 :: 写法,这被称为“方法引用”,而双冒号是一种新的语法。
当Lambda表达式所要完成的业务逻辑已经存在(已经有函数实现了),就直接引用该方法即可。
方法引用符 双冒号 :: 为引用运算符,而它所在的表达式被称为方法引用。如果Lambda要表达的函数方案已经存在于某个方法的实现中,那么则可以通过双冒号来引用该方法作为Lambda的替代者。
语义分析 例如上例中, System.out 对象中有一个重载的 println(String) 方法恰好就是我们所需要的。那么对于printString 方法的函数式接口参数,对比下面两种写法,完全等效:
Lambda表达式写法: s -> System.out.println(s);
方法引用写法: System.out::println
第一种语义是指:拿到参数之后经Lambda之手,继而传递给 System.out.println 方法去处理。
第二种等效写法的语义是指:直接让 System.out 中的 println 方法来取代Lambda。两种写法的执行效果完全一样,而第二种方法引用的写法复用了已有方案,更加简洁。
注:Lambda 中 传递的参数 一定是方法引用中 的那个方法可以接收的类型,否则会抛出异常
推导与省略 如果使用Lambda,那么根据“可推导就是可省略”的原则,无需指定参数类型,也无需指定的重载形式——它们都将被自动推导。而如果使用方法引用,也是同样可以根据上下文进行推导。
函数式接口是Lambda的基础,而方法引用是Lambda的孪生兄弟。
下面这段代码将会调用 println 方法的不同重载形式,将函数式接口改为int类型的参数:
@FunctionalInterface public interface PrintableInteger { void print (int str) ; }
由于上下文变了之后可以自动推导出唯一对应的匹配重载,所以方法引用没有任何变化:
public class Demo03PrintOverload { private static void printInteger (PrintableInteger data) { data.print(1024 ); } public static void main (String[] args) { printInteger(System.out::println); } }
这次方法引用将会自动匹配到 println(int) 的重载形式。
方法引用的底层实现 反编译以下代码:
public static void main (String[] args) { printString(s -> { System.out.println(s); }); printString(System.out::println); } public static void printString (Printable p) { p.print("HelloWorld" ); }
lambda表达式的编译结果:
生成一个方法,将函数体放到该方法中
public static void main (String[] args) { Demo01Printable.printString((Printable)LambdaMetafactory .metafactory(null , null , null , (Ljava/lang/String;)V, lambda$main$0 (java.lang.String ), (Ljava/lang/String;)V)()); } private static void lambda$main$0 (String s) p.print("HelloWorld" ); }
lambda方法引用的编译结果:
原本的lambda$main$被替换为了println函数
public static void main (String[] args) { PrintStream printStream = System.out; Objects.requireNonNull(printStream); Demo01Printable.printString((Printable)LambdaMetafactory .metafactory(null , null , null , (Ljava/lang/String;)V, println(java.lang.String ), (Ljava/lang/String;)V)((PrintStream)printStream)); }
方法实体:
public class PrintStream { public void println (String x) { synchronized (this ) { print(x); newLine(); } } }
方法引用基于Lambda实现,二者本质相同,都是使用匿名内部类。
方法引用语法格式 所有的方法都可以被引用,除了抽象方法,因为抽象方法没有方法体。
格式
范例
类方法 类名 :: 静态方法
Integer :: parseInt
构造方法 类名 :: new
Student :: new
实例方法 对象 :: 成员方法
通过对象名引用成员方法 这是最常见的一种用法,与上例相同。如果一个类中已经存在了一个成员方法:
public class MethodRefObject { public void printUpperCase (String str) { System.out.println(str.toUpperCase()); } }
函数式接口仍然定义为:
@FunctionalInterface public interface Printable { void print (String str) ; }
那么当需要使用这个 printUpperCase 成员方法来替代 Printable 接口的Lambda的时候,已经具有了MethodRefObject 类的对象实例,则可以通过对象名引用成员方法,代码为:
public class Demo04MethodRef { private static void printString (Printable lambda) { lambda.print("Hello" ); } public static void main (String[] args) { MethodRefObject obj = new MethodRefObject (); printString(obj::printUpperCase); } }
通过类名称引用静态方法 由于在 java.lang.Math 类中已经存在了静态方法 abs ,所以当我们需要通过Lambda来调用该方法时,有两种写法。首先是函数式接口:
@FunctionalInterface public interface Calcable { int calc (int num) ; }
第一种写法是使用Lambda表达式:
public class Demo05Lambda { private static void method (int num, Calcable lambda) { System.out.println(lambda.calc(num)); } public static void main (String[] args) { method(‐10 , n ‐> Math.abs(n)); } }
但是使用方法引用的更好写法是:
public class Demo06MethodRef { private static void method (int num, Calcable lambda) { System.out.println(lambda.calc(num)); } public static void main (String[] args) { method(‐10 , Math::abs); } }
在这个例子中,下面两种写法是等效的:
Lambda表达式: n -> Math.abs(n)
方法引用: Math::abs
通过super引用成员方法 如果存在继承关系,当Lambda中需要出现super调用时,也可以使用方法引用进行替代。首先是函数式接口:
@FunctionalInterface public interface Greetable { void greet () ; }
然后是父类 Human 的内容:
public class Human { public void sayHello () { System.out.println("Hello!" ); } }
最后是子类 Man 的内容,其中使用了Lambda的写法:
public class Man extends Human { @Override public void sayHello () { System.out.println("大家好,我是Man!" ); } public void method (Greetable g) { g.greet(); } public void show () { method(()‐>{ new Human ().sayHello(); }); method(()‐>new Human ().sayHello()); method(()‐>super .sayHello()); } }
但是如果使用方法引用来调用父类中的 sayHello 方法会更好,例如另一个子类 Woman :
public class Man extends Human { @Override public void sayHello () { System.out.println("大家好,我是Man!" ); } public void method (Greetable g) { g.greet(); } public void show () { method(super ::sayHello); } }
在这个例子中,下面两种写法是等效的:
Lambda表达式: () -> super.sayHello()
方法引用: super::sayHello
通过this引用成员方法 this代表当前对象,如果需要引用的方法就是当前类中的成员方法,那么可以使用 this::成员方法 的格式来使用方法引用。首先是简单的函数式接口:
@FunctionalInterface public interface Richable { void buy () ; }
下面是一个丈夫 Husband 类:
public class Husband { private void marry (Richable lambda) { lambda.buy(); } public void beHappy () { marry(() ‐> System.out.println("买套房子" )); } }
开心方法 beHappy 调用了结婚方法 marry ,后者的参数为函数式接口 Richable ,所以需要一个Lambda表达式。但是如果这个Lambda表达式的内容已经在本类当中存在了,则可以对 Husband 丈夫类进行修改:
public class Husband { private void buyHouse () { System.out.println("买套房子" ); } private void marry (Richable lambda) { lambda.buy(); } public void beHappy () { marry(() ‐> this .buyHouse()); } }
如果希望取消掉Lambda表达式,用方法引用进行替换,则更好的写法为:
public class Husband { private void buyHouse () { System.out.println("买套房子" ); } private void marry (Richable lambda) { lambda.buy(); } public void beHappy () { marry(this ::buyHouse); } }
在这个例子中,下面两种写法是等效的:
Lambda表达式: () -> this.buyHouse()
方法引用: this::buyHouse
类的构造器引用 由于构造器的名称与类名完全一样,并不固定。所以构造器引用使用 类名称::new 的格式表示。首先是一个简单Person 类:
public class Person { private String name; public Person (String name) { this .name = name; } public String getName () { return name; } public void setName (String name) { this .name = name; } }
然后是用来创建 Person 对象的函数式接口:
public interface PersonBuilder { Person buildPerson (String name) ; }
要使用这个函数式接口,可以通过Lambda表达式:
public class Demo09Lambda { public static void printName (String name, PersonBuilder builder) { System.out.println(builder.buildPerson(name).getName()); } public static void main (String[] args) { printName("赵丽颖" , name ‐> new Person (name)); } }
但是通过构造器引用,有更好的写法:
public class Demo10ConstructorRef { public static void printName (String name, PersonBuilder builder) { System.out.println(builder.buildPerson(name).getName()); } public static void main (String[] args) { printName("赵丽颖" , Person::new ); } }
在这个例子中,下面两种写法是等效的:
Lambda表达式: name -> new Person(name)
方法引用: Person::new
数组的构造器引用 数组也是 Object 的子类对象,所以同样具有构造器,只是语法稍有不同。如果对应到Lambda的使用场景中时,
@FunctionalInterface public interface ArrayBuilder { int [] buildArray(int length); }
在应用该接口的时候,可以通过Lambda表达式:
public class Demo11ArrayInitRef { private static int [] initArray(int length, ArrayBuilder builder) { return builder.buildArray(length); } public static void main (String[] args) { int [] array = initArray(10 , length ‐> new int [length]); } }
但是更好的写法是使用数组的构造器引用:
public class Demo12ArrayInitRef { private static int [] initArray(int length, ArrayBuilder builder) { return builder.buildArray(length); } public static void main (String[] args) { int [] array = initArray(10 , int []::new ); } }
在这个例子中,下面两种写法是等效的:
Lambda表达式: length -> new int[length]
方法引用: int[]::new
Stream流 引言 说到Stream便容易想到I/O Stream,而实际上,谁规定“流”就一定是“IO流”呢?在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream 概念,用于解决已有集合类库既有的弊端。
传统集合的多步遍历代码几乎所有的集合(如 Collection 接口或 Map 接口等)都支持直接或间接的遍历操作。而当我们需要对集合中的元素进行操作的时候,除了必需的添加、删除、获取外,最典型的就是集合遍历。例如:
import java.util.ArrayList;import java.util.List;public class Demo01ForEach { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("张无忌" ); list.add("周芷若" ); list.add("赵敏" ); list.add("张强" ); list.add("张三丰" ); for (String name : list) { System.out.println(name); } } }
这是一段非常简单的集合遍历操作:对集合中的每一个字符串都进行打印输出操作。
循环遍历的弊端 Java 8的Lambda让我们可以更加专注于做什么 (What),而不是怎么做 (How),这点此前已经结合内部类进行了对比说明。现在,我们仔细体会一下上例代码,可以发现:
for循环的语法就是“怎么做 ”
for循环的循环体才是“做什么 ”
为什么使用循环?因为要进行遍历。但循环是遍历的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从第一个到最后一个顺次处理的循环 。前者是目的,后者是方式。
试想一下,如果希望对集合中的元素进行筛选过滤:
将集合A根据条件一过滤为子集B ;
然后再根据条件二过滤为子集C 。
那怎么办?在Java 8之前的做法可能为:
import java.util.ArrayList;import java.util.List;public class Demo02NormalFilter { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("张无忌" ); list.add("周芷若" ); list.add("赵敏" ); list.add("张强" ); list.add("张三丰" ); List<String> zhangList = new ArrayList <>(); for (String name : list) { if (name.startsWith("张" )) { zhangList.add(name); } } List<String> shortList = new ArrayList <>(); for (String name : zhangList) { if (name.length() == 3 ) { shortList.add(name); } } for (String name : shortList) { System.out.println(name); } } }
这段代码中含有三个循环,每一个作用不同:
首先筛选所有姓张的人;
然后筛选名字有三个字的人;
最后进行对结果进行打印输出。
每当我们需要对集合中的元素进行操作的时候,总是需要进行循环、循环、再循环。这是理所当然的么?不是。 循环是做事情的方式,而不是目的。另一方面,使用线性循环就意味着只能遍历一次。如果希望再次遍历,只能再使用另一个循环从头开始。
那,Lambda的衍生物Stream能给我们带来怎样更加优雅的写法呢?
Stream的更优写法 下面来看一下借助Java 8的Stream API,什么才叫优雅:
import java.util.ArrayList;import java.util.List;public class Demo03StreamFilter { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("张无忌" ); list.add("周芷若" ); list.add("赵敏" ); list.add("张强" ); list.add("张三丰" ); list.stream() .filter(s ‐> s.startsWith("张" )) .filter(s ‐> s.length() == 3 ) .forEach(System.out::println); } }
直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:获取流、过滤姓张、过滤长度为3、逐一打印 。代码中并没有体现使用线性循环或是其他任何算法进行遍历,我们真正要做的事情内容被更好地体现在代码中。
流式思想 概述 注意:请暂时忘记对传统IO流的固有印象!
整体来看,流式思想类似于工厂车间的“ 生产流水线”。
当需要对多个元素进行操作(特别是多步操作)的时候,考虑到性能及便利性,我们应该首先拼好一个“模型”步骤 方案,然后再按照方案去执行它。这是一种集合元素的处理方案,而方案就是一种“函数模型”。
这里的 filter 、 map 、 skip 都是在对函数模型进行操作,集合元素并没有真正被处理 。只有当终结方法 count执行的时候,整个模型才会按照指定策略执行操作。而这得益于Lambda的延迟执行特性 。
备注:“Stream流”其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)。
Stream(流)是一个来自数据源的元素队列
元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
数据源 流的来源。 可以是集合,数组 等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
Pipelining : 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如**延迟执行(laziness)和短路( short-circuiting)**。内部迭代 : 以前对集合遍历都是通过Iterator或者增强for的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式,流可以直接调用遍历方法。
当使用一个流的时候,通常包括三个基本步骤:获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道。
特点 专注于对容器对象的聚合操作
提供串行/并行 两种模式
使用Fork/Join框架 拆分任务
提高编程效率、可读性
获取流 -> 中间操作 -> 终结操作
获取流 java.util.stream.Stream<T> 是Java 8新加入的最常用的流接口(这并不是一个函数式接口)。获取一个流非常简单,有以下几种常用的方式:
根据Collection获取流 首先, java.util.Collection 接口中加入了default方法 stream 用来获取流,所以其所有实现类均可获取流。
import java.util.*;import java.util.stream.Stream;public class Demo04GetStream { public static void main (String[] args) { List<String> list = new ArrayList <>(); Stream<String> stream1 = list.stream(); Set<String> set = new HashSet <>(); Stream<String> stream2 = set.stream(); Vector<String> vector = new Vector <>(); Stream<String> stream3 = vector.stream(); } }
根据Map获取流 java.util.Map 接口不是 Collection 的子接口,且其K-V数据结构不符合流元素的单一特征,所以获取对应的流需要分key、value或entry等情况:
import java.util.HashMap;import java.util.Map;import java.util.stream.Stream;public class Demo05GetStream { public static void main (String[] args) { Map<String, String> map = new HashMap <>(); Stream<String> keyStream = map.keySet().stream(); Stream<String> valueStream = map.values().stream(); Stream<Map.Entry<String, String>> entryStream = map.entrySet().stream(); } }
根据数组获取流 如果使用的不是集合或映射而是数组,由于数组对象不可能添加默认方法,所以 Stream 接口中提供了静态方法of ,使用很简单:
import java.util.stream.Stream;public class Demo06GetStream { public static void main (String[] args) { String[] array = { "张无忌" , "张翠山" , "张三丰" , "张一元" }; Stream<String> stream = Stream.of(array); } }
备注: of 方法的参数其实是一个可变参数,所以支持数组。
常用方法 流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
延迟方法 :返回值类型仍然是 Stream 接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为延迟方法。)
终结方法 :返回值类型不再是 Stream 接口自身类型的方法,因此不再支持类似 StringBuilder 那样的链式调用。本小节中,终结方法包括 count 和 forEach 方法。
中间操作(Intermediate)
map (mapToInt, flatMap 等)、 filter 、 distinct、 sorted、 peek、 limit 、 skip 、 parallel、 sequential、 unordered、concat
终结操作(Terminal)
forEach 、 forEachOrdered、 toArray 、 reduce、 collect 、 min、 max、 count 、 iterator、anyMatch、 allMatch、 noneMatch、 findFirst、 findAny
逐一处理:forEach 虽然方法名字叫 forEach ,但是与for循环中的“for-each”昵称不同。
void forEach (Consumer<? super T> action) ;
该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理。
复习Consumer接口 java.util.function.Consumer<T>接口是一个消费型接口。 Consumer接口中包含抽象方法void accept (T t) ,意为消费一个指定泛型的数据。
基本使用: import java.util.stream.Stream;public class Demo12StreamForEach { public static void main (String[] args) { Stream<String> stream = Stream.of("张无忌" , "张三丰" , "周芷若" ); stream.forEach(name‐> System.out.println(name)); } }
过滤:filter 可以通过 filter 方法将一个流转换成另一个子集流。方法签名:
Stream<T> filter (Predicate<? super T> predicate) ;
该接口接收一个 Predicate 函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
复习Predicate接口 此前我们已经学习过 java.util.stream.Predicate 函数式接口,其中唯一的抽象方法为:
该方法将会产生一个boolean值结果,代表指定的条件是否满足。如果结果为true,那么Stream流的 filter 方法将会留用元素;如果结果为false,那么 filter 方法将会舍弃元素。
基本使用 Stream流中的 filter 方法基本使用的代码如:
import java.util.stream.Stream;public class Demo07StreamFilter { public static void main (String[] args) { Stream<String> original = Stream.of("张无忌" , "张三丰" , "周芷若" ); Stream<String> result = original.filter(s ‐> s.startsWith("张" )); } }
在这里通过Lambda表达式来指定了筛选的条件:必须姓张。
映射:map 如果需要将流中的元素映射到另一个流中,可以使用 map 方法。方法签名:
<R> Stream<R> map (Function<? super T, ? extends R> mapper) ;
该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
复习Function接口 此前我们已经学习过 java.util.stream.Function 函数式接口,其中唯一的抽象方法为:
这可以将一种T类型转换成为R类型,而这种转换的动作,就称为“映射”。
基本使用 Stream流中的 map 方法基本使用的代码如:
import java.util.stream.Stream;public class Demo08StreamMap { public static void main (String[] args) { Stream<String> original = Stream.of("10" , "12" , "18" ); Stream<Integer> result = original.map(str‐>Integer.parseInt(str)); } }
这段代码中, map 方法的参数通过方法引用,将字符串类型转换成为了int类型(并自动装箱为 Integer 类对象)。
统计个数:count 正如旧集合 Collection 当中的 size 方法一样,流提供 count 方法来数一数其中的元素个数:
该方法返回一个long值代表元素个数(不再像旧集合那样是int值)。基本使用:
import java.util.stream.Stream;public class Demo09StreamCount { public static void main (String[] args) { Stream<String> original = Stream.of("张无忌" , "张三丰" , "周芷若" ); Stream<String> result = original.filter(s ‐> s.startsWith("张" )); System.out.println(result.count()); } }
取用前几个:limit limit 方法可以对流进行截取,只取用前n个。方法签名:
Stream<T> limit (long maxSize) ;
参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。基本使用:
import java.util.stream.Stream;public class Demo10StreamLimit { public static void main (String[] args) { Stream<String> original = Stream.of("张无忌" , "张三丰" , "周芷若" ); Stream<String> result = original.limit(2 ); System.out.println(result.count()); } }
跳过前几个:skip 如果希望跳过前几个元素,可以使用 skip 方法获取一个截取之后的新流:
如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用:
import java.util.stream.Stream;public class Demo11StreamSkip { public static void main (String[] args) { Stream<String> original = Stream.of("张无忌" , "张三丰" , "周芷若" ); Stream<String> result = original.skip(2 ); System.out.println(result.count()); } }
组合:concat 如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat :
static <T> Stream<T> concat (Stream<? extends T> a, Stream<? extends T> b)
备注:这是一个静态方法,与 java.lang.String 当中的 concat 方法是不同的。
该方法的基本使用代码如:
import java.util.stream.Stream;public class Demo12StreamConcat { public static void main (String[] args) { Stream<String> streamA = Stream.of("张无忌" ); Stream<String> streamB = Stream.of("张翠山" ); Stream<String> result = Stream.concat(streamA, streamB); } }
收集器:collect import java.util.*;import java.util.stream.Collectors;import java.util.stream.Stream;public class Demo06Stream_collect { public static void main (String[] args) { List<String> list = new ArrayList <String>(); list.add("林青霞" ); list.add("张曼玉" ); list.add("王祖贤" ); list.add("柳岩" ); Stream<String> listStream = list.stream().filter(s -> s.length() == 3 ); List<String> names = listStream.collect(Collectors.toList()); for (String name : names) { System.out.println(name); } Set<Integer> set = new HashSet <Integer>(); set.add(10 ); set.add(20 ); set.add(30 ); set.add(33 ); set.add(35 ); Stream<Integer> setStream = set.stream().filter(age -> age > 25 ); Set<Integer> ages = setStream.collect(Collectors.toSet()); for (Integer age : ages) { System.out.println(age); } String[] strArray = {"林青霞,30" , "张曼玉,35" , "王祖贤,33" , "柳岩,25" }; Stream<String> arrayStream = Stream.of(strArray).filter( s -> Integer.parseInt(s.split("," )[1 ]) > 28 ); Map<String, Integer> map = arrayStream.collect(Collectors.toMap( s -> s.split("," )[0 ], s -> Integer.parseInt(s.split("," )[1 ]) )); Set<String> keySet = map.keySet(); for (String key : keySet) { System.out.println(key + ",," + map.get(key)); } } }